Training a Super-Resolution Network with Random Shapes

To see if a super-resolution can generalize from randomly generated shapes to real world, we trained EDSR [2] with images that are generated randomly. One of them can be seen above. Images from 800 to 810 from DIV2K [1] are used for evalution between epochs during training.
To create images similar to the above, we used gaussian distribution with different means and standart deviations for different variables. The settings to create above image are given below. The same settings are used to create training images.
- color_mean = (R: 114.35629928, G: 111.561547, B: 103.1545782)
- color_std = (R: 72.45974394708261, G: 68.87470687936465, B: 74.47221978843599)
- background_color = color_mean
- width = 2048: Image Width
- height = 1080: Image Height
- max_size = 96: Max Shape Size
- position_x = Uniform(low=0, high=width)
- position_y = Uniform(low=0, high=height)
- Shape is chosen randomly between circle and rectangle;
- Circle
- radius = Gaussian(mean=max_size/4, std=max_size/10)
- Rectangle
- width = Gaussian(mean=max_size/2, std=max_size/5)
- height = Gaussian(mean=max_size/2, std=max_size/5)
- yaw = Uniform(low=0, high=2π)
- Circle
- color = Gaussian(mean=color_mean, std=color_std): Calculated for each channel separately.
- number_of_shapes = 10000
Color mean and standart deviation are calculated from DIV2K [1] 001-800 images.
Training
We trained the network the same as the paper [2] except the patch size. We used patch size of 24 instead of 192 to train it faster. The network trained both with DIV2K [1] and the custom dataset in x2 scale for comparison.
Loss
Although we stopped training for the random shapes earlier because it wasn’t getting any better in terms of PSNR, it’s loss was lower than the DIV2K [1]. It seems that learning this type of image type is far easier and I think it is due to the sharp gradient changes and being noise free.
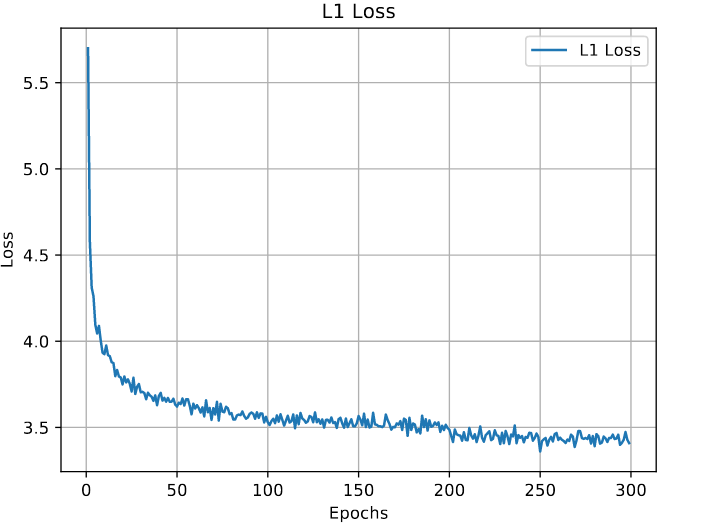
DIV2K
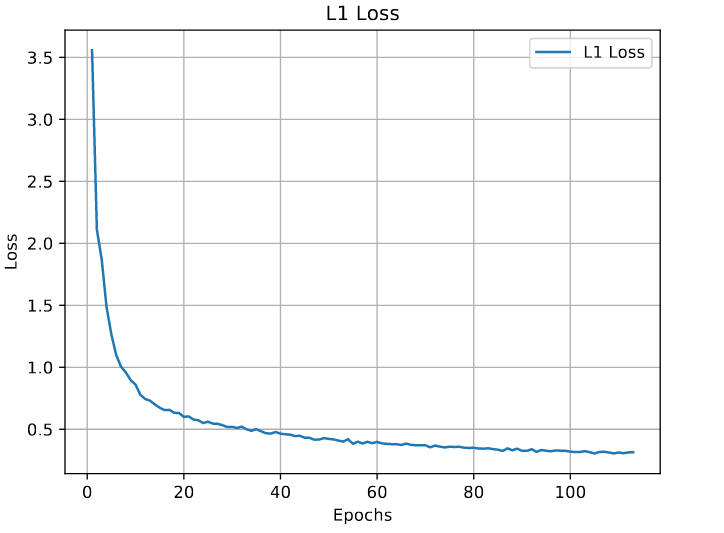
Random Shapes
PSNR
While loss decrease looks promising, random shapes’ PSNR during training didn’t performed as good as DIV2K [1] PSNR. In fact random shapes’ PSNR decreased instead of rising as the training goes.
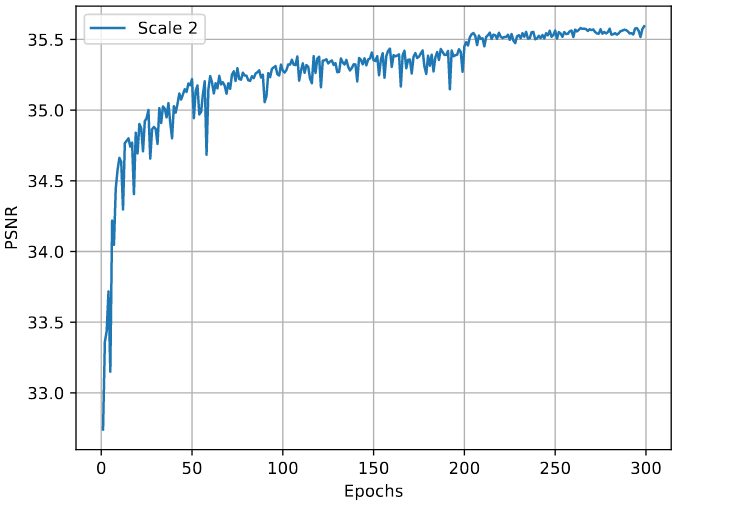
DIV2K
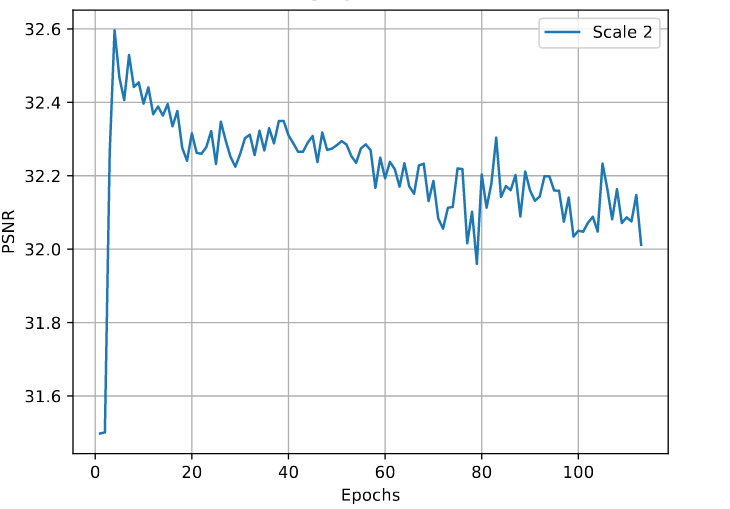
Random Shapes
Conclusion
In conclusion, a network trained with a dataset that has only colorful rectangles and circles can’t generalize to real world applications. If everything was colorful rectangles and circles, the network might have generalized.
Code
https://github.com/goktug97/randomshapes
References
- Agustsson, E., & Timofte, R. (2017). NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops.
- Bee Lim and Sanghyun Son and Heewon Kim and Seungjun Nah and Kyoung Mu Lee (2017). Enhanced Deep Residual Networks for Single Image Super-ResolutionCoRR, abs/1707.02921.